前言 在 Python 中,访问网络资源最有名的库就是 requests 、aiohttp 和 httpx 。一般情况下,requests 只能发送同步请求;aiohttp 只能发送异步请求;httpx 既能发送同步请求,又能发送异步请求。
下面,就着重介绍一下 httpx 的使用方法。
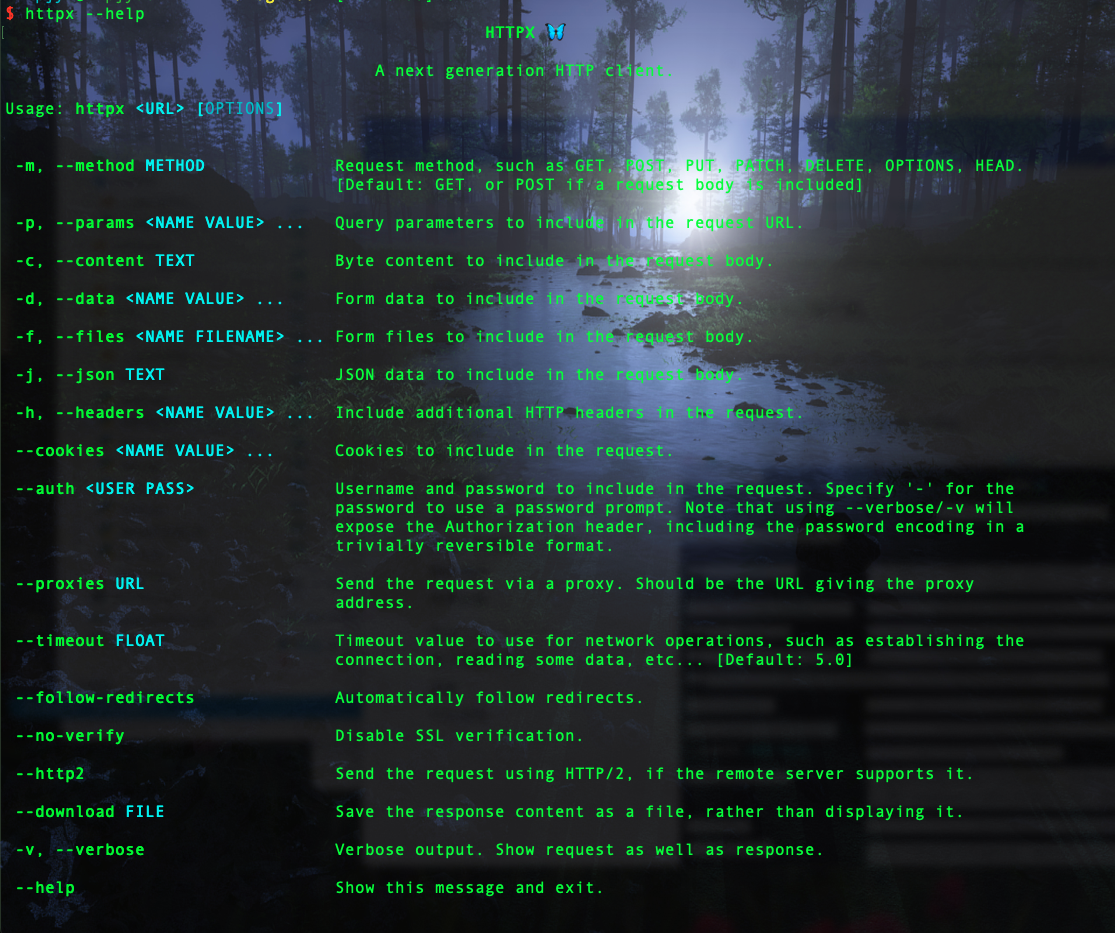
安装 使用 pip 安装 httpx:
当然了,httpx 也可以使用命令行操作。不过,需要按如下命令安装。
1 pip install 'httpx[cli]'
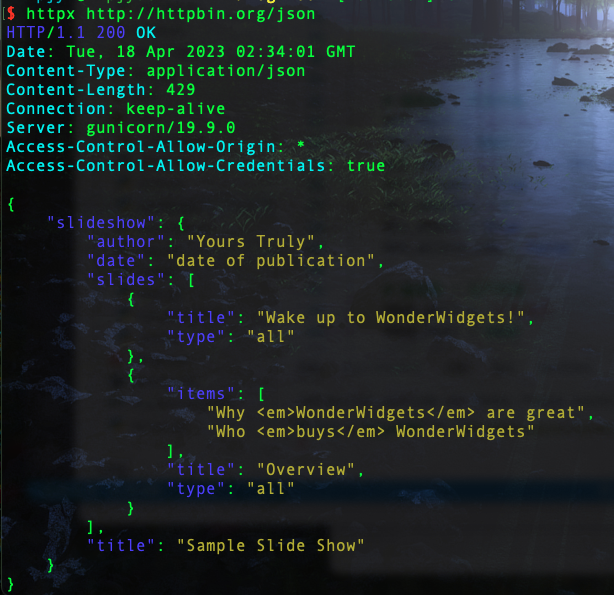
命令行测试发送请求:
快速入门 发起 GET 请求 直接用 get 方法,如下:
1 2 3 4 5 import httpx.get ('https://httpbin.org/get' )print (r.status_code) print (r.text)
对于带参数的 URL,传入一个 dict 作为 params 参数,如下:
1 2 3 4 5 import httpx.get ('https://httpbin.org/get' , params={'q' : 'python' , 'cat' : '1001' })print (r.url) print (r.text)
对于特定类型的响应,例如 JSON,可以直接获取,如下:
1 2 3 4 r = httpx.get('https://httpbin.org/get' )# {'args' : {}, 'headers' : {'Accept' : '*/*' , 'Accept-Encoding' : ...
对于非文本响应,响应内容也可以以字节的形式访问,如下:
1 2 >>> r.content<!doctype html > \n<html > \n<head > \n<title > Example Domain</title > ...'
需要传入 HTTP Header 时,我们传入一个 dict 作为 headers 参数,如下:
1 r = httpx.get('https://www.baidu.com/' , headers={'User-Agent' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit' })
获取响应头,如下:
1 2 3 4 5 r.headerse': ' text /html; charset=utf-8 ', ' Transfer-Encoding ': ' chunked', ' Content-Encoding ': ' gzip', ...} r.headers[' Content-Type'] # ' text /html; charset=utf-8 '
发起 POST 请求 要发送 POST 请求,只需要把 get()方法变成 post(),然后传入 data 参数作为 POST 请求的数据,如下:
1 r = httpx.post('https://accounts.baidu.com/login' , data={'form_email' : 'abc@example.com' , 'form_password' : '123456' })
httpx 默认使用 application/x-www-form-urlencoded 对 POST 数据编码。如果要传递 JSON 数据,可以直接传入 json 参数,如下:
1 2 params = {'key' : 'value' }r = httpx.post(url, json=params)
发起二进制请求 1 2 content = b'Hello, world' r = httpx.post("https://httpbin.org/post" , content=content)
上传文件 上传文件操作如下:
1 2 upload_files = {'upload-file' : open('report.xls' , 'rb' )}r = httpx.post('https://httpbin.org/post' , files=upload_files)
如果需要在上传文件时包含非文件数据字段,请使用 data 参数,如下:
1 2 3 4 data = {'message' : 'Hello, world!' }'file' : open('report.xls' , 'rb' )}"https://httpbin.org/post" , data =data, files =files)print (r.text)
流媒体响应 可以流式传输响应的二进制内容:
1 2 3 >>> with httpx.stream("GET" , "https://www.example.com" ) as r:... for data in r.iter_bytes(): ... print (data)
或者返回文本:
1 2 3 >>> with httpx.stream("GET" , "https://www.example.com" ) as r:... for text in r.iter_text(): ... print (text)
或者逐行流式传输:
1 2 3 >>> with httpx.stream("GET" , "https://www.example.com" ) as r:... for line in r.iter_lines(): ... print (line)
添加 Cookie 在请求中传入 Cookie,只需准备一个 dict 传入 cookies 参数,如下:
1 2 cs = {'token' : '12345' , 'status' : 'working' }r = httpx.get(url, cookies=cs)
httpx 对 Cookie 做了特殊处理,使得我们不必解析 Cookie 就可以轻松获取指定的 Cookie,如下:
1 2 r.cookies['token']# 12345
指定超时 默认超时为 5 秒。要指定超时,传入以秒为单位的 timeout 参数。超时分为连接超时和读取超时,如下:
1 2 3 4 5 try :get (url, timeout =(3.1 , 27 ))as e:
当然,也可以禁用超时:
1 httpx.get ('https://github.com/' , timeout =None)
超时重连 1 2 3 4 5 6 7 8 def gethtml(url):0 while i < 3 :try :get (url, timeout =5 ).text return html1
重定向 默认情况下,httpx 不会遵循所有 HTTP 方法的重定向,不过可以使用 follow_redirects 开启重定向:
1 2 3 4 5 6 7 >>> r = httpx.get('http://github.com/' , follow_redirects=True ) >>> r.url >>> r.status_code >>> r.history
高级用法 使用 httpx.Client() ,实际上是调用 HTTP 链接池。可以带来显著的性能改进。包括:减少跨请求的延迟(无需握手),减少 CPU 使用和往返,减少网络拥塞。
用法 使用 Client 的推荐方式是作为上下文管理器。这将确保在离开 with 块时正确清理连接:
1 2 with httpx.Client() as client:
或者,可以使用.close()显式关闭连接池,而无需使用块:
1 2 3 4 5 client = httpx.Client()try :finally :client .close()
发送请求 一旦有了 Client,您可以使用.get().post()等发送请求。例如:
1 2 3 4 5 >>> with httpx.Client() as client:... r = client.get('https://example.com' ) ... >>> r
跨请求共享配置 Client 允许您通过将参数传递给 Client 构造函数来将配置应用于所有传出请求:
1 2 3 4 5 6 7 >>> url = 'http://httpbin.org/headers' >>> headers = {'user-agent' : 'my-app/0.0.1' } >>> with httpx.Client(headers=headers) as client:... r = client.get(url) ... >>> r.json()['headers' ]['User-Agent' ]
此外,base_url 允许您为所有传出请求预留 URL:
1 2 3 4 5 >>> with httpx.Client(base_url='http://httpbin.org' ) as client:... r = client.get('/headers' ) ... >>> r.request.url
监控下载进度 如果您需要监控大响应的下载进度,您可以使用响应流并检查 responseresponse.num_bytes_downloaded 属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 import tempfile.NamedTemporaryFile () as download_file:"https://speed.hetzner.de/100MB.bin" .stream ("GET" , url) as response:print ('response' , response)int (response.headers ["Content-Length" ] )print ('total' , total)for chunk in response.iter_bytes ():.write (chunk).num_bytes_downloaded / totalprint ('percent: {:.2%}' .format (percent))
添加代理 httpx 支持通过 proxies 参数设置 HTTP 代理:
1 2 with httpx.Client(proxies ="http://localhost:8030" ) as client:
对于更高级的用例,请传递代理 dict。例如,要将 HTTP 和 HTTPS 请求路由到 2 个不同的代理,分别位于 http://localhost:8030 和 http://localhost:8031,请传递代理 URL:
1 2 3 4 5 6 7 proxies = {"http://" : "http://localhost:8030" ,"https://" : "http://localhost:8031" ,with httpx.Client(proxies =proxies ) as client:
代理凭据可以作为代理 URLuserinfo 部分传递:
1 2 3 4 proxies = {"http://" : "http://username:password@localhost:8030" ,
异步支持 发送异步请求 1 2 3 4 5 >>> async with httpx.AsyncClient() as client:... r = await client.get('https://www.example.com/' ) ... >>> r
打开和关闭 Client 使用 with:
1 2 async with httpx.AsyncClient() as client:
显式关闭客户端:
1 2 3 client = httpx.AsyncClient()
流媒体响应 1 2 3 4 >>> client = httpx.AsyncClient() >>> async with client.stream('GET' , 'https://www.example.com/' ) as response:... async for chunk in response.aiter_bytes(): ... ...
异步响应流方法有:
Response.aread()-用于有条件地读取流块内的响应。 Response.aiter_bytes()-用于将响应内容流化为字节。 Response.aiter_text()-用于将响应内容流化为文本。 Response.aiter_lines()-用于将响应内容流式传输为文本行。 Response.aiter_raw()-用于流式传输原始响应字节,无需应用内容解码。 Response.aclose()-用于结束回复。您通常不需要这个,因为.stream 块会在退出时自动关闭响应。 更多编程教学请关注公众号:潘高陪你学编程